This was a service and WordPress plugin for users to upload their social media data files to the cloud, and then import their content into their WordPress blog. Facebook was supported first, then Twitter, and then Instagram and TikTok. It was planned to import Reddit and Tumblr content as well. Status updates, images, and videos could be turned into blog posts. It had advanced filtering and grouping capabilities so that a group of small status updates could create a single blog post, or grouped into multiple blog posts depending on the interval (day / week / month / or tag).
The code projects were pushed to git repositories on AWS CodeCommit.
In June 2025, the service was shut down and the plugin was removed because it wasn't as popular as hoped. It didn't make sense to continuously support it with new WordPress versions (retest and reupload) if barely anyone was using it. There were a few marketing campaigns, but the ad expenses were just too high and it failed to convert enough.
Below are technical details about the skills, technologies, and services used to create and support this app.
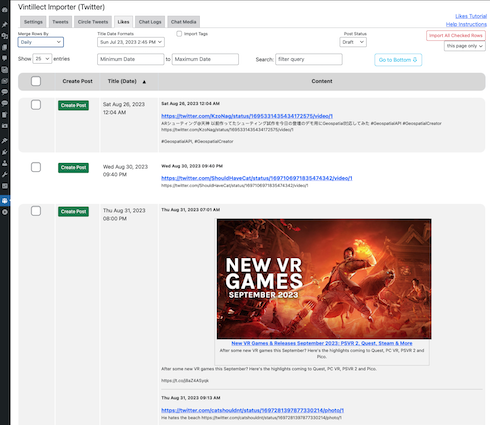
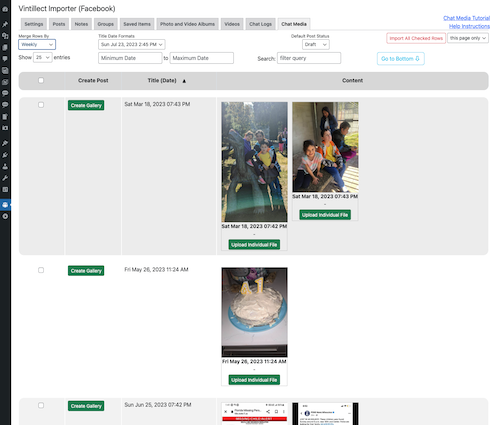
At first, the plugin only supported importing Facebook posts, and later it was extended to import tweets from X (Twitter). The user only needed to enter in a secret upload ID that was sent out by email once their data file was processed.
The plugin requested JSON files from a secret AWS S3 URL. The jQuery scripts parsed the JSON and created rows in the data table for each post. The grouping option made it possible to group the posts by time period (day/week/month), tag, or social group name. That was useful for when the user created many small status updates that didn't need an entire blog post for each.
The user could filter by date range and then process all posts within that date range. Meaning, it would automatically create those blog posts.
You may be wondering, why not just make it so that the entire data files could be uploaded into the WordPress site or simply unzipped to an S3 location without processing them? Here are the three main reasons:
How was this service supposed to generate revenue to cover operating costs?
While creating blog posts was free, it didn't import the images and videos without a small service fee on the Vintillect website. The user could preview the media, but not import them without paying.
Private chat messages and media also required small service fees. Family and friends share photos with each other, and so this service made it easy to discern which photos/videos to import and make available on a public blog to archive.
There were discounts provided for return customers, newsletter opt-in, and displaying small banner ads at the bottom of blog posts to refer traffic to Vintillect Importer.
For various reasons, it was better to upload large files to S3 rather than directly to a server. The upload form used an S3 APIs to upload large files in chunks and in parallel for faster uploads if the user's computer was capable of it.
The large data files were uploaded to an S3 bucket, an AWS Lambda function (Python script) unzipped (uncompressed) the file, and stored the unzipped files in a separate bucket. The Lambda function sends a request to the Vintillect server (web hook) letting it know that the files are ready to be processed.
The secret upload ID forms the first part of the S3 key, and indexing was disallowed so that no one can browse files and directories (S3 keys / URL parts). This made the URLs only available to the user who had the secret upload ID.
The uploaded files on S3 expired after 7 days (automatically deleted). This was to protect user privacy and not become a hacker target. Don't store private data any longer than you have to.

When the user fills out a short form (name, email, upload), it gets stored in a MySQL database table, along with the upload ID. When the Lambda function notifies the web hook that the upload is finished, it stores the exact S3 key prefix and creates a job record. The job record contains fields for current stage, status, error log, and etc. A cron job queries this table for jobs with a ready status and stage.
There are actually different job scripts for social media services and their various JSON files. The cron job is a Python script that manages the stages and which script to call next. A common script is included to provide commonly used functions.
The scripts process a specific JSON file, makes requests to generate link preview data, and create standard formatted JSON files to be requested and processed by the WordPress plugin scripts. S3 URL paths for post-attached media are also included.
Chat transcripts are put into HTML and compressed to a zip file. To discourage abuse of chat privacy, it was not included in the ability to post chat transcripts to a blog. Also, the zip file was only made available to the user with a small fee.
When it completed, it sent an email to the user stating that it was done and provided the secrete upload ID to enter into the WordPress plugin.