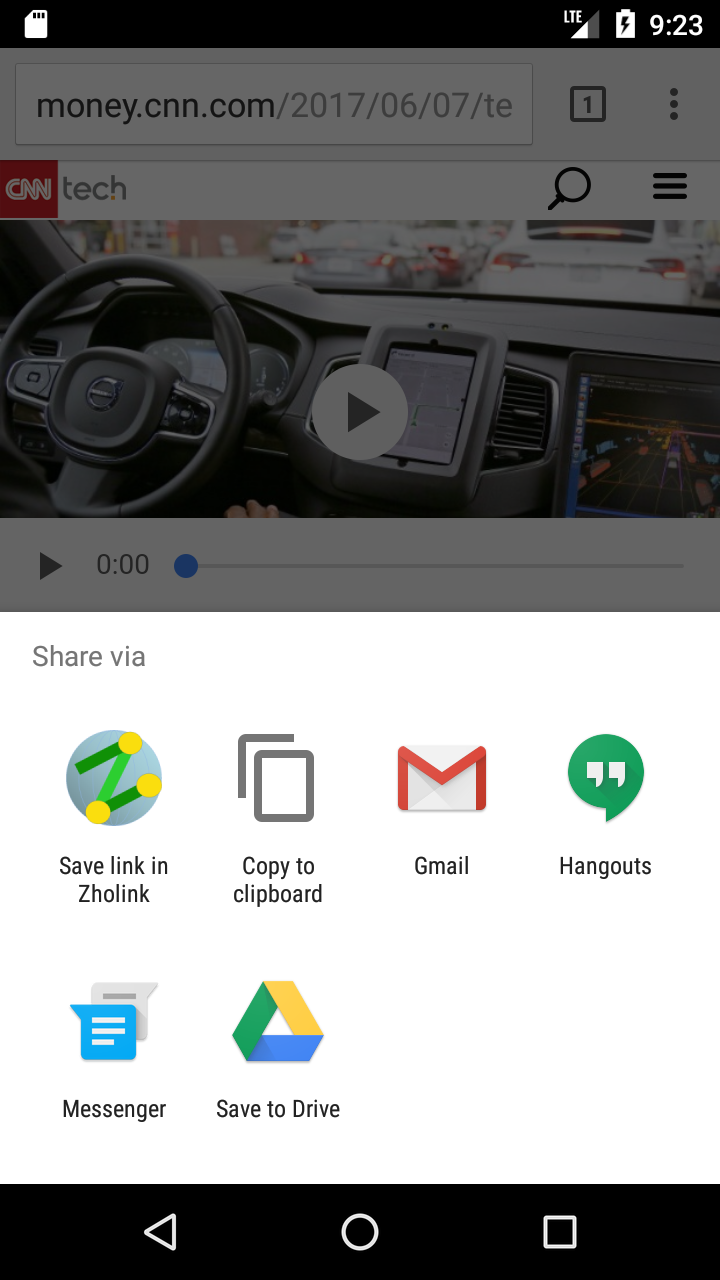
Do you have a hundred bookmarks, a hundred tabs open in your browser, or send yourself links to look at later? This app (and service) was a way for you to save thousands of links and categorize them for easy browsing.
The initial motivation for this app was for something completely different. It would serve as a method for curating web pages by tag, category, and emotional reaction. This data could then be used by machine learning and search relevance algorithms. The purpose was to help AI understand relationships between entities and be able to automatically categorize web pages and content by topic.
Like the WordPress plugin, this app failed to generate enough interest and downloads. There are millions of apps out there and it was difficult to get noticed in the app stores. Marketing failed to generate enough interest and income to cover the server expenses.
Below are technical details about the skills, technologies, and services used to create and support this app.

This project was started back in 2008. Cordova was a popular project to build cross platform apps and React Native was just getting started. Both projects lacked advanced capabilities such as being able to share a URL from a web page to the app and receiving notifications. So the apps were developed using Java in Android Studio and Swift in Apple's XCode.
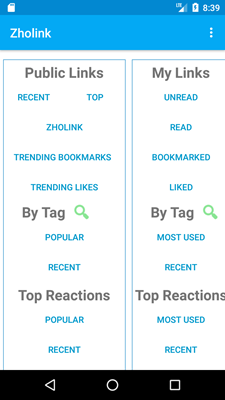
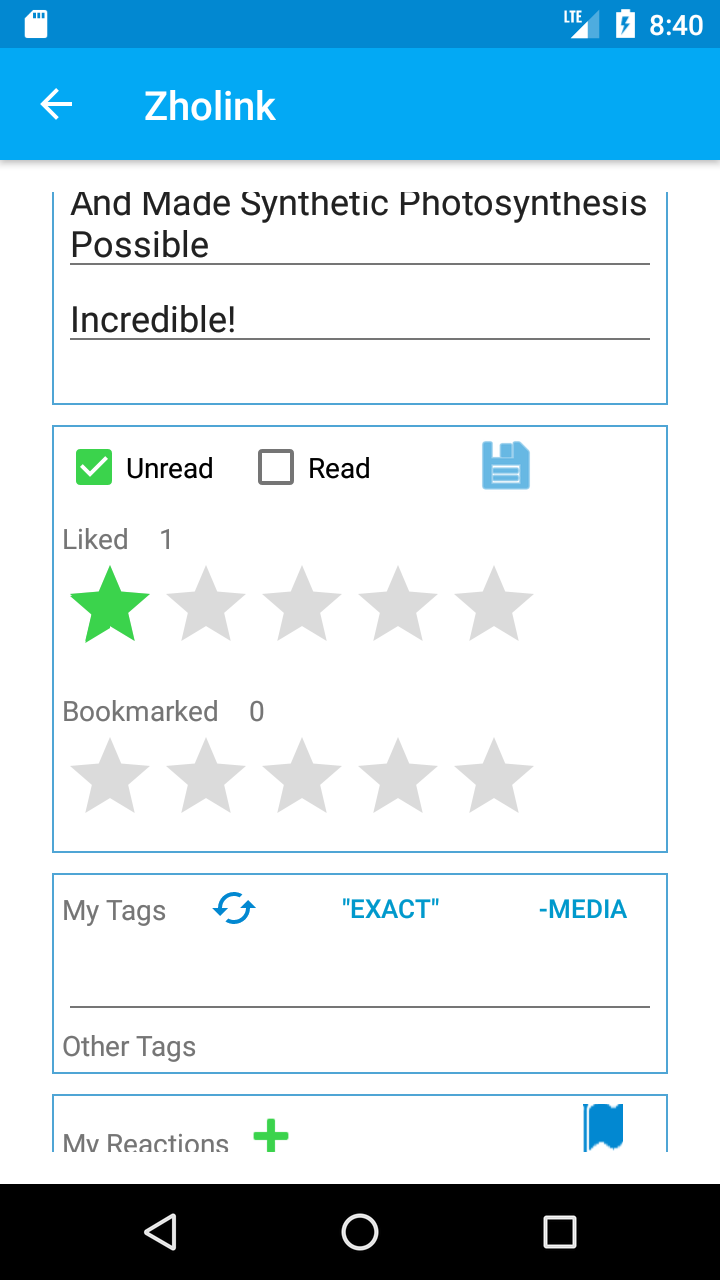
The main screen was divided into two complimentary columns, Public Links and My Links. Public Links came from aggregated data, such as most recently submitted, top submitted links, currently trending (bookmarks or just likes). Popular and recently submitted tags and reactions to links. The My Links columns contains only the links that the user has submitted to be saved. They can mark the link as unread or read, and bookmarked or just liked. They can add tags and (emotional) reactions to links to help them organize their links. The tags could be popular topics such as celebrity names. An example of a reaction could be "funny" for links to memes.
Links and lists were stored on Zholink servers through an API. Data was cached on the app for offline browsing browsing or slow internet connectivity.
To deter spam abuse, users were required to authenticate through an OAuth service, such as Google, Facebook, Microsoft, or Yahoo. Once they were authenticated through a web page, they received a temporary authentication code. The user could just easily share the authentication link to the Zholink app and be authenticated that way.
The web server served the web pages and API. When a link was shared through the app and to the server, a request was sent to that link to retrieve the page and parse link preview data. That link preview information was then sent back to the app. It contained the URL, title, descriptions, keywords, and preview image. This data was often found in the web page meta tags, especially since web pages started including them so they can be shared easily through Facebook and Twitter. The code to make these requests and parse the data was custom developed since no libraries at the time could adequately parse the preview data the way it was needed or generate preview data based on other relevant HTML tags.
The web application was built using MVC architecture in ASP .Net and C#; developed with Visual Studio Professional. Unit tests, integration tests, and mock data were created. The front end used CDNs for Bootstrap, jQuery, and Font Awesome.
It contained an Admin portal and dashboard that showed charts for user registrations and devices. There were tables for AWS CloudWatch events and error counts.
Long before AWS CodeCommit and CodeDeploy, developers used other methods for deploying their latest changes initializing new servers. AMIs were created and automatically ran a PowerShell script that installed the necessary Windows and .Net libraries; copied the compressed Zholink website from S3; installed the website onto IIS.
MongoDB was used to store and aggregate data. The aggregate data was used to create top and trending public lists, using JavaScript functions deployed to MongoDB Atlas cloud service. There were model classes, data access layer, interfaces, and mock data (for testing).
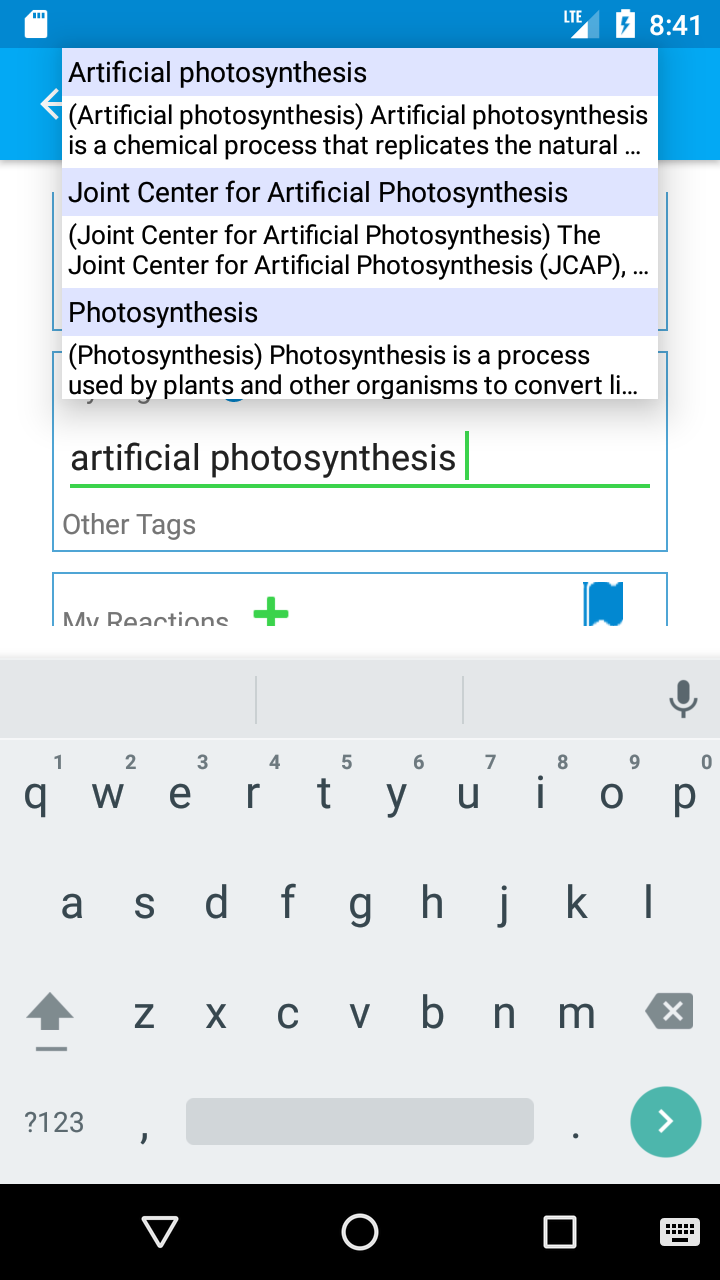
Data was pulled in from other sources as well to provide faceted tags used in the tag autosuggest feature. Ultimately though, Wikipedia topics and titles were used for tag names. Please donate to the Wikimedia Foundation.
Initially, entity relationships (for use in AI) were thought to be hierarchical, so DMOZ (the Open Directory Project) taxonomy was used as a data source. This seemingly great idea for organizing topics was later rejected since entity relationships aren't fully hierarchical. There are is-a and has-a relationships, but there are others too. Also, hierarchical relationships of topics can be subjective.